Kmeans_1 Question The K -means algorithm is a method to automatically cluster similar data examples together. Concretely, you are given a training set , and want to group the data into a few cohesive “clusters”.
理论基础 Kmeans属于无监督学习(Unsupervised Learning)中的一个方法,主要用于对已有数据进行分类以及确定每个聚类的中心位置,这样我们在获得一个新的未分类点时就可以对其进行预测,看它属于哪一个聚类。具体操作如下:选定k个聚点,然后针对各数据点分别对所有聚点求范数(求距离)。如果数据点a距离聚点A距离最小,则将a归类在A的聚类。对所有数据点进行这样的操作之后,我们就将数据点进行了第一次的分类。接着我们让聚点A的坐标更改为所有归类于A的聚类的平均坐标。即将A改为此时聚类的中心位置。对其他聚点也进行这样的操作。接着我们继续求范数,改坐标的操作。如果初始聚点位置选取合理,经过多次循环,我们就能得到最终的分类结果。
数据读取处理 1 2 3 4 5 6 7 8 9 10 11 12 import numpy as np import scipy.io as sio import matplotlib.pyplot as plt data1=sio.loadmat('./Kmeans_1.mat') data1.keys() dict_keys(['__header__', '__version__', '__globals__', 'X']) X=data1['X'] X.shape (300, 2)
1 2 plt.scatter(X[:,0 ],X[:,1 ]) plt.show()
数据点归类 1 2 3 4 5 6 7 8 9 10 def find_centroids(X,centros): idx=[] for i in range(len(X)): dist = np.linalg.norm((X[i]-centros),axis=1) id_i=np.argmin(dist) idx.append(id_i) return np.array(idx)
1 2 3 4 5 centros=np.array([[3,3],[6,2],[8,5]]) idx=find_centroids(X,centros) idx[:3] array([0, 2, 1], dtype=int64)
移动聚点 1 2 3 4 5 6 7 def compute_centros(X,idx,k): centros=[] for i in range(k): centros_i=np.mean(X[idx==i],axis=0) centros.append(centros_i) return np.array(centros)
1 2 3 4 compute_centros(X,idx,k=3) array([[2.42830111, 3.15792418], [5.81350331, 2.63365645], [7.11938687, 3.6166844 ]])
最终循环代码 1 2 3 4 5 6 7 8 9 10 11 def run_kmeans (X,centros,iters ): k=len (centros) centros_all=[] centros_all.append(centros) centros_i=centros for i in range (iters): idx=find_centroids(X,centros_i) centros_i=compute_centros(X,idx,k) centros_all.append(centros_i) return idx,np.array(centros_all)
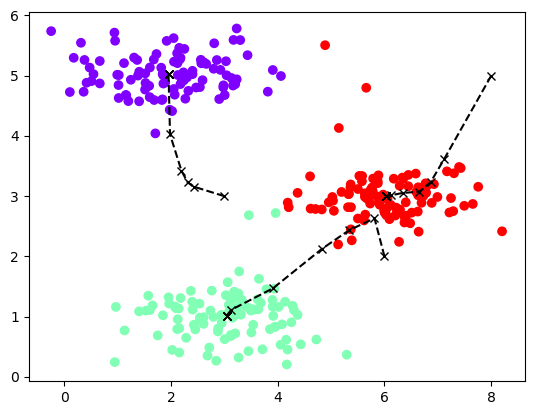
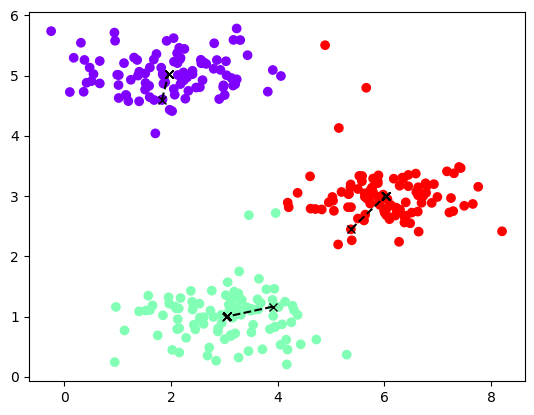
画图 1 2 3 4 def plot_data(X,centros_all,idx): plt.figure() plt.scatter(X[:,0],X[:,1],c=idx,cmap='rainbow') plt.plot(centros_all[:,:,0],centros_all[:,:,1],'kx--')
1 2 idx,centros_all=run_kmeans(X,centros,iters=10) plot_data(X,centros_all,idx)
下面我们随机选取3个数据点作为初始聚点,看看聚点的初始选择对结果的影响。
1 2 3 def init_centros (X,k ): index=np.random.choice(len (X),k) return X[index]
1 2 3 4 init_centros(X,k=3) array([[3.91596068, 1.01225774], [1.97619886, 4.43489674], [5.72395697, 3.04454219]])
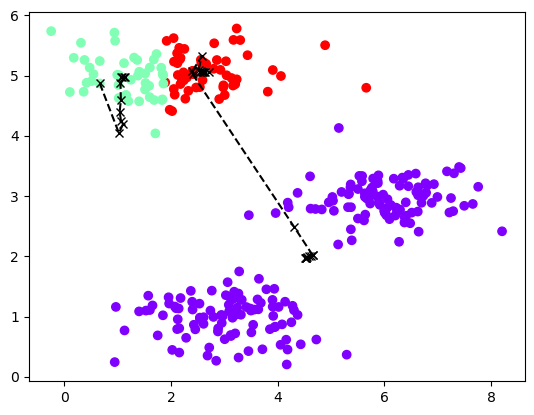
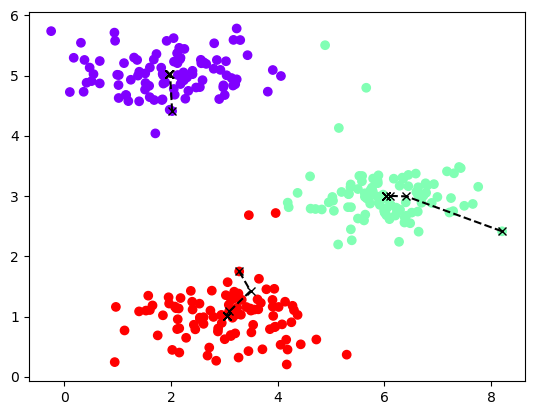
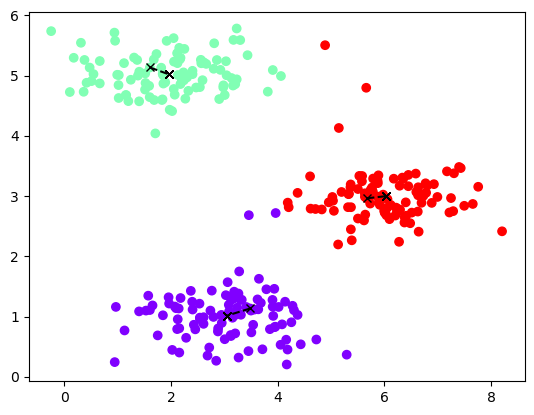
1 2 3 for i in range(4): idx,centros_all=run_kmeans(X,init_centros(X,k=3),iters=10) plot_data(X,centros_all,idx)
由第一幅图可以看见,当我们初始聚点为这样时,最终的分类效果并不令人满意,它将一体的数据强行分为了两块,将两块分离的数据强行合在了一起。
Site 代码(Jupyter)和所用数据:https://github.com/codeYu233/Study/tree/main/Kmeans_1
Note 该题与数据集均来源于Coursera上斯坦福大学的吴恩达老师机器学习的习题作业,学习交流用,如有不妥,立马删除